Chapter 1: Fundamentals of Quantitative Design and Analysis¶
约 3009 个字 1 张图片 预计阅读时间 10 分钟
引言¶
持续几十年的两个半导体工艺规律在当下难以维系,分别为:
- 登纳德缩放比例定律(Dennard scaling)
- 摩尔定律(Moore's Law)
其中,前者迫使行业转向高效的多处理器或多核设计以替代低效的单处理器架构,标志着处理器性能的提升从单纯依赖指令级并行(instruction-level parallelism,ILP)转向数据级并行(data-level parallelism,DLP)和线程级并行(thread-level parallelism,TLP)。
对于后者,有以下 4 个原因导致了处理器性能的提升速度放缓:
- 由于摩尔定律的放缓和登纳德缩放比例定律的终结,晶体管不再大幅改进。
- 微处理器的功耗预算不变。
- 用多个高能效处理器代替了单个大功耗的处理器。
- 多重处理已达到 Amdahl 定律的上限。
提升能耗 - 性能 - 成本的唯一途径就是专用。未来的微处理器将包含几个领域专用核,它们只能很好地执行某一类计算,但执行这类计算的性能远优于通用核,从而引入了领域专用体系结构(domain-specific architecture)。
计算机的分类¶
下表总结了当下的五种主流计算环境与其重要特征。
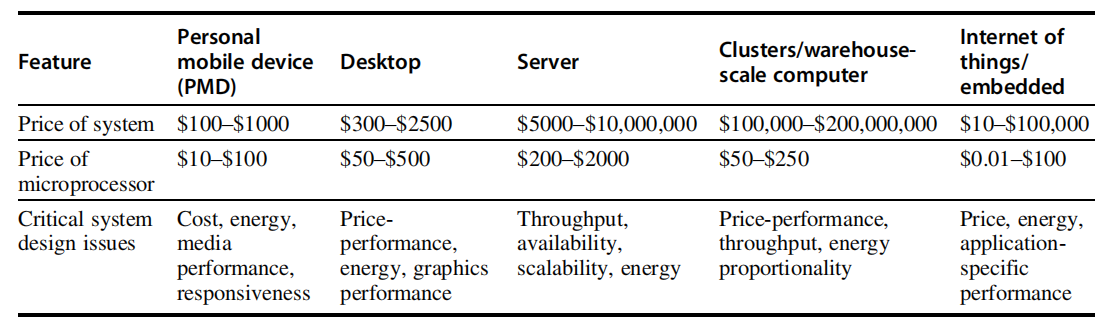
物联网 / 嵌入式计算机¶
物联网(Internet of Things,IoT)指通常以无线方式连接到互联网的嵌入式计算机。
个人移动设备¶
个人移动设备(personal mobile device,PMD)是指带有多媒体用户界面的无线设备,比如手机、平板计算机等。
PMD 中的处理器经常被视为嵌入式计算机,但我们将其看作一个单独的类别,这是因为 PMD 是可以运行外部开发软件的平台,它们与桌面计算机有许多共同特征。其他嵌入式设备在硬件和软件复杂性方面都有很大的限制。我们将能否运行第三方软件作为区分嵌入式计算机和非嵌入式计算机的标准。
响应性能和可预测性能是多媒体应用程序的关键特征。实时性能需求是指应用程序的一个程序段有一个确定的最大执行时间。
服务器¶
服务器的关键特征不同于桌面计算机,主要包括:
- 可用性
- 可扩展性
- 高吞吐能力
集群 / 仓库级计算机¶
集群是指一组桌面计算机或服务器通过局域网连接在一起,其运转方式类似于一台更大型的计算机。每个节点都运行自己的操作系统,节点之间使用网络协议进行通信。最大规模的集群称为仓库级计算机(WSC),其设计方式使数万台服务器像一台服务器一样运行。
WSC 与服务器的相似之处在于,可用性对它们来说非常重要。超级计算机与 WSC 的相似之处在于它们都非常昂贵。而二者的不同之处在于,超级计算机强调浮点性能,运行大型的、通信密集的批程序,这些程序可能会一次运行几个星期;而 WSC 强调交互式应用程序、大规模存储、可靠性和高互联网带宽。
并行度与并行体系结构的分类¶
在所有计算机类别中,多种级别的并行度已成为计算机设计的驱动力,而能耗和成本则是主要约束。应用程序中主要有以下两种并行。
- 数据级并行(DLP):之所以出现,是因为有许多数据项可以同时操作。
- 任务级并行(TLP):之所以出现,是因为创建的工作任务可以单独执行并且主要采用并行方式执行。
计算机硬件又以如下四种主要方式来利用这两种类型的应用并行。
- 指令级并行:在两个层面对数据级并行进行了利用,首先在编译器的帮助下,借助流水线之类的思想适度利用,其次借助推测执行(speculative execution)之类的思想进一步利用。
- 向量体系结构、图形处理器(graphic processor unit,GPU)和多媒体指令集(multimediainstruction set):将单条指令并行应用于一组数据,以利用数据级并行。
- 线程级并行:在一种紧耦合硬件模型中利用数据级并行或任务级并行,这种模型允许并行线程之间进行交互。
- 请求级并行:利用程序员或操作系统指定的大量解耦任务之间的并行性。
Michael Flynn 提出了一种简单的分类方式,我们今天仍在使用这种分类的缩写。它们针对的是数据级并行和任务级并行。他对指令流与数据流中的并行进行了研究,在多处理器受限制最多的组件中,指令非常需要上述并行。根据研究结果,他将所有计算机划分为以下 4 类。
- 单指令流单数据流(single instruction stream,single data stream,SISD):这个类别是单处理器。程序员把它看作标准的顺序计算机,但可以利用指令级并行。
- 单指令流多数据流(single instruction stream,multiple data streams, SIMD):同一指令由多个使用不同数据流的处理器执行。SIMD 计算机利用数据级并行,对多个数据项并行执行相同的操作。每个处理器都有自己的数据存储器,但只有一个指令存储器和控制处理器,用来提取和分派指令。
- 多指令流单数据流(multiple instruction streams,single data stream,MISD):到目前为止,还没有这种类型的商用多处理器,但包含这种类型之后,这种简单的分类方式才完整。
- 多指令流多数据流(multiple instruction streams,multiple data streams,MIMD):每个处理器都提取自己的指令,对自己的数据进行操作,它针对的是任务级并行。一般来说,MIMD 比 SIMD 更灵活,所以适用性也更强,但它比 SIMD 更贵一些。例如,MIMD 计算还能利用数据级并行,当然,其开销可能要比 SIMD 计算机高一些。这种开销意味着粒度要足够大,以便高效地利用并行度。
这种分类模型很粗略,许多并行处理器其实是 SISD、SIMD 和 MIMD 的混合类型。
计算机体系结构的定义¶
体系结构涵盖计算机设计的所有三个方面:指令集体系结构、组成或微体系结构、硬件。
指令集体系结构(instruction set architecture,ISA)相当于软件和硬件之间的界线。ISA 包括以下七个方面:
- ISA 分类
- 栈架构(stack architecture)
- 累加器架构(accumulator architecture)
- 通用目的寄存器架构(general-purpose register architecture, GRA)
- 寄存器 - 存储器 ISA:任何指令都能访问内存
- 载入 - 存储 ISA:只有加载和存储指令才能访问内存
- 存储器寻址:几乎所有 ISA 都使用字节寻址。有些体系结构要求操作对象必须是对齐的。对于不要求对齐的体系结构,若操作数对齐,访问速度通常会更快一些。
- 寻址模式
- 操作数的类型和大小
- 操作指令:常见的操作类别为数据传输指令、算术逻辑指令、控制指令和浮点指令。
- 控制流指令:几乎所有 ISA 都支持条件分支、无条件跳转、过程调用和返回。
- ISA 编码
- 固定长度
- 可变长度
组成 / 微体系结构(organization / microarchitecture):计算机设计的高阶内容,如存储器系统、存储器互连、内部处理器或 CPU 的设计。
硬件是指计算机的具体实现,包括计算机的逻辑设计和封装技术。
技术趋势¶
现代计算机实现中不可或缺的 5 种实现技术:
- 集成电路逻辑技术
- 半导体 DRAM
- 半导体闪存
- 磁盘技术
- 网络技术
性能趋势¶
带宽和吞吐量是指在给定时间内完成的总工作量。与之相对,延迟或响应时间是指一个事件从开始到完成所经过的时间。一个简单的经验法则是:带宽的增加速度至少是延迟改进速度的平方。
晶体管性能与连线¶
集成电路的制造工艺用特征尺寸(feature size)来衡量,即一个晶体管或一条连线在 x 轴方向或 y 轴方向的最小尺寸。由于每平方毫米硅片上的晶体管数目由单个晶体管的表面积决定,所以当特征尺寸线性减小时,晶体管密度将呈二次方增长。
晶体管性能的提升更加复杂。大致来说,晶体管性能的提高与特征尺寸的减小呈线性关系。当特征尺寸减小时,晶体管性能线性提升,而晶体管数目呈二次方增加。
尽管晶体管的性能通常会随着特征尺寸的减小而提升,但集成电路中的连线却不会如此。具体来说,一段连线的信号延迟与其电阻和电容的乘积成正比。当然,当特征尺寸减小时,连线会变短,但单位长度的电阻和电容都会变差。一般来说,与晶体管性能相比,连线延迟方面的改进十分微小。在过去几年中,除了功耗限制之外,连线延迟已经成为大型集成电路的主要设计障碍。信号在连线上的传播延迟消耗了越来越多的时钟周期,而功耗对时钟周期的影响大于连线延迟。
集成电路中的功耗和能耗趋势¶
功耗和能耗:系统视角¶
从系统架构师的角度来看,共有 3 个主要关注事项:
- 处理器需要的最大功耗。
- 持续功耗,或通常称为热设计功耗(thermal design power,TDP),因为该指标是对系统散热提出的要求。
- 能耗和能效。功耗为单位时间的能耗。一般来说,能耗更适合用于对比处理器,因为它与特定任务以及该项任务所需要的时间相关联。具体来说,执行一项工作负载的能耗等于平均功耗乘以此项工作负载的执行时间。
微处理器内部的能耗和功耗¶
对 CMOS 芯片而言,传统的主要能耗源是开关晶体管,也称为动态能耗(dynamic energy)。每个晶体管的能耗与该晶体管驱动的容性负载与电压平方的乘积成正比:
这个公式的计算结果就是逻辑转换脉冲 0 → 1 → 0 或 1 → 0 → 1 的能耗。那么一次转换(0 → 1或 1 → 0)的能耗即为:
每个晶体管所需要的功耗就是一次转换的能耗与转换频率的乘积:
对于一项固定任务,降低时钟频率可以降低功耗,但不会降低能耗。显然,通过降低电压可以大幅降低动态功耗与能耗。容性负载的大小取决于输出端连接的晶体管数目及所用技术,而该技术决定了连线和晶体管的电容。